Scrappy
Scrappy - A simple web scraper
A multi-source directory scraper for extracting company data from partner and directory platforms, built with Next.js and TypeScript.
Extract company information (names, websites, contact details, locations) from Shopify Partners, Clutch.co, and white-labeled Partner Page directories with a single tool. Designed for business development and lead generation workflows.
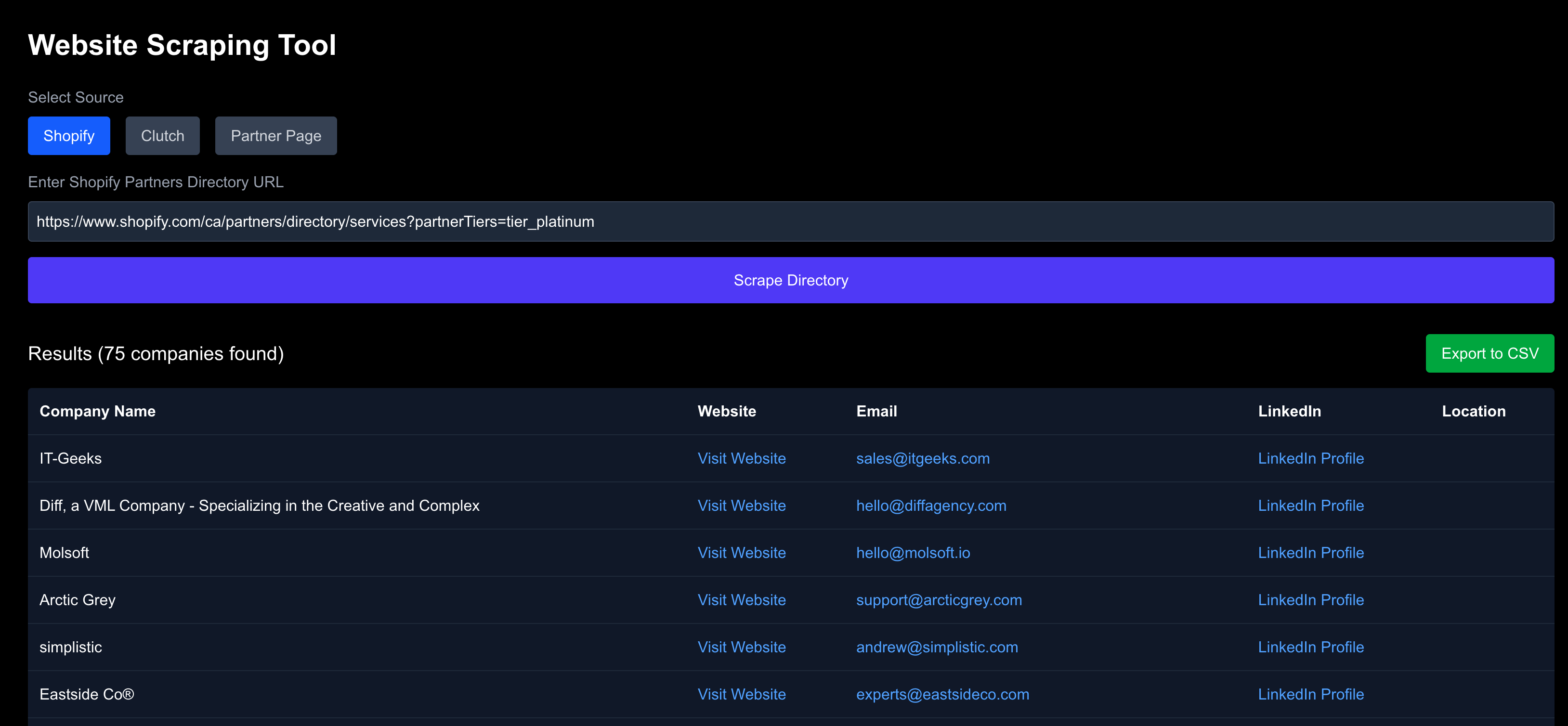
Check out this screenshot:
Features
- Multi-source scraping: Support for Shopify Partners Directory, Clutch.co directories, and white-labeled Partner Page instances
- Dynamic profile URLs: Automatically constructs profile URLs for any Partner Page domain
- Pagination support: Automatically scrapes multiple pages for Shopify directories
- Featured listing filtering: Excludes promotional/featured listings from Clutch results
- CSV export: Export scraped data with source-specific formatting
- Anti-bot handling: Uses Puppeteer with stealth features to bypass Cloudflare and bot detection
- Dynamic content loading: Scrolls pages and waits for lazy-loaded content to ensure complete data extraction
- Clean dark UI: Modern interface with responsive table displays and real-time scraping status
Built With
- Next.js — Full-stack React framework with API routes
- TypeScript — Type-safe development for reliability
- Puppeteer — Headless browser automation for dynamic content
- Cheerio — Server-side HTML parsing for static content
- Axios — HTTP client for web requests
- Tailwind CSS — Utility-first styling for modern UI
- React — Component-based UI development

